Co musisz wiedzieć o SRE i Site Reliability Engineering?
W dzisiejszym dynamicznym świecie IT, gdzie usługi online muszą działać 24/7, pojęcie SRE (Site Reliability Engineering) wurde sehr populär. Ale czym jest SRE i dlaczego ta metodologia staje się standardem w branchenübergreifend IT? W tym artykule poznasz wszystko, co musisz wiedzieć o inżynierii niezawodności, roli SRE oderaz jej związku z DevOps.
Standortzuverlässigkeitstechnik to więcej niż tylko metodologia - to Podejście do zarządzania systemami informatycznymi, które łączy najlepsze praktyki z zakresu inżynierii oprogramowania z tradycyjnym zarządzanieminfrastrukturą. SRE to przyszłość nowoczesnych operacji IT, która pozwala organizacjom osiągnąć niespotykane poziomy niezawodności przy jednoczesnym przyspieszeniu wdrażania nowych funkcjonalności.
Czym jest SRE?
Definicja Website-Zuverlässigkeit
Standortzuverlässigkeitstechnik to dyscyplina, która została po raz pierwszy wprowadzona przez Google jako odpowiedź na wyzwania związane z prowadzeniem usług internetowych na dużą skalę. SRE łączy tradycyjne operacje systemowe z metodami inżynierii oprogramowania, tworząc unikalne Podejście do zarządzania systemami.
Inżynier SRE zu specjalista, który współpracuje z zespołami developerskimi i działami operacyjnymi, aby zapewnić, że systemy działają niezawodnie, są skalowalne i łatwe w utrzymaniu. SRE nie jest tylko administratorem systemu - zu inżynier, który myśli o infrastruktur jak programmista o kodzie.
Historia inżynierii niezawodności
Inżynieria niezawodności narodziła się z potrzeby radzenia sobie z rosnącą złożonością nowoczesnych systemówinformatycznych. Tradycyjne podejście, w którym zespoły odpowiedzialne za rozwój i operacje działały w izolacji, okazało się niewystarczające w erze chmurowych usług i mikrousług.
Google jako pierwsze zdefiniowało SRE jako metodologię, która pozwala wdrażać i utrzymywać systemy o skali globalnej. Dzisiaj SRE jest stosowane przez największe firmy technologiczne na świecie, od Netflix po Amazon.
Dlaczego niezawodność jest kluczowa?
W erze cyfrowej transformacji niezawodność usług stała się kluczowa dla sukcesu biznesowego. Każdy przestój może kosztować miliony dolarów i utratę zaufania klientów. SRE oferuje strukturalne podejście do zapewniania dostępności usług na poziomie, który spełnia oczekiwania współczesnych użytkowników.
Stabilność i dostępność nie są już opcjonalne - to podstawowe wymagania, które determinują konkurencyjność na rynku. SRE zapewnia ramy do osiągnięcia tych celów w sposób efektywny i skalowalny.
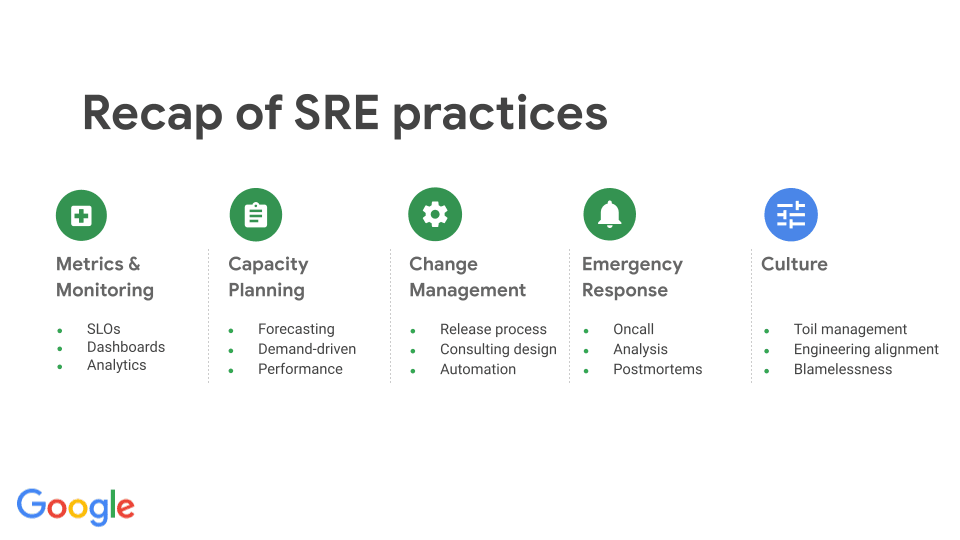
Jakie są główne obowiązki inżyniera SRE?
Rola SRE w zespole IT
Rola SRE w organizacji jest wieloaspektowa i wykracza daleko poza tradycyjne operacje systemowe. Inżynier SREpełni funkcję łącznika między zespołami rozwoju a operacjami, zapewniając, że nowe funkcje są wdrażane bez uszczerbku dla niezawodności.
Zespół SRE jest odpowiedzialny za:
- Überwachung des Systems i Reagowanie na problemy
- Automatische Abläufe operacyjnych
- Projektowanie i implementację systemów monitorowania
- Zarządzanie incydentami i analizę przyczyn źródłowych
- Współpracę z zespołami programistycznymi przy projektowaniu odpornych architektur
SRE odgrywają kluczową rolę w kulturze organizacyjnej, promując myślenie o niezawodności jako integralnej części procesu rozwoju oprogramowania.
Monitorowanie i zarządzanie incydentami
Jednym z najważniejszych aspektów pracy SRE scherzen Überwachung i zarządzanie incydentami. SRE wykorzystują zaawansowane narzędzia do monitorowania, takich jak Prometheus, Grafana, DataDog czy PagerDuty, aby śledzić zdrowie systemów w czasie rzeczywistym.
Zarządzanie incydentami w metodologii SRE opiera się na jasno zdefiniowanych procesach:
- Szybka detekcja problemów dzięki automatycznemu monitorowaniu
- Efektywne eskalowanie zgłoszeń do odpowiednich ekspertów
- Minimalizacja czasu reakcji na incydent
- Analiza post-mortem dla identyfikacji przyczyn źródłowych
- Implementacja ulepszeń zapobiegających podobnym problemom
SRE są odpowiedzialni za szybkie diagnozowanie i rozwiązywanie problemów, ale równie ważne jest uczenie się z każdego incydentu i ulepszanie systemów.
Automatyzacja procesów i systemów
Automatyzacja stanowi serce filozofii SRE. Celem jest zmniejszenie ryzyka błędów ludzkich i zwiększenie efektywności operacyjnej. SRE aktywnie programują rozwiązania, które automatyzują rutynowe zadania operacyjne.
Kluczowe obszary automatyzacji w SRE obejmują:
- Wdrożenia aplikacji przy użyciu narzędzi jak Kubernetes, Ansible czy Terraform
- Automatische Abläufe skalowania infrastruktur
- Automatyczne reagowanie na typowe incydenty
- Zarządzanie infrastrukturą jako kod (IaC)
- Automatyczne testowanie i walidację systemów
Automatyzacja nie tylko zwiększa wydajnośćale także pozwala inżynierom skupić się na bardziej strategicznych zadaniach.
Jak DevOps współpracuje z SRE?
Różnice między DevOps a SRE
Choć DevOps i SRE często są mylone, istnieją między nimi istotne różnice. DevOps to szeroka filozofia kulturowa i organizacyjna, podczas gdy SRE to konkretna implementacja zasad DevOps z silnym naciskiem na niezawodność.
DevOps koncentruje się na łamaniu barier między zespołami rozwoju a operacjami, podczas gdy SRE idzie krok dalej, definiując konkretne praktyki i metryki. SRE można postrzegać jako "implementację DevOps z inżynierskim podejściem do Operationen“.
Praktyki DevOps w inżynierii niezawodności
SRE wykorzystuje kluczowe praktyki DevOps, ale adaptuje je do specyficznych potrzeb inżynierii niezawodności:
- Kontinuierliche Integration/kontinuierliche Bereitstellung - ale z dodatkowymi mechanizmami bezpieczeństwa
- Infrastruktur als Code - z naciskiem na niezawodność i możliwość odtworzenia
- Überwachung i obserwabilność - ale z głębszym poziomem szczegółowości
- Współpraca między zespołami - ale z jasno zdefiniowanymi rolami i odpowiedzialnościami
SRE bierze najlepsze elementy DevOps i dodaje do nich rygorystyczne podejście inżynierskie.
Wspólna kultura zespołów
Sukces SRE zależy od kultury współpracy między wszystkimi zespołami w organizacji. SRE promuje kulturę, w której niezawodność jest odpowiedzialnością każdego - od entwickeln po Produktbesitzer.
Kluczowe elementy tej kultury to:
- Dzielenie odpowiedzialności za dostępność systemów
- Transparentność w komunikacji o problemach i incydentach
- Die Prozesse sind so gestaltet, dass sie sich gegenseitig ergänzen.
- Równowaga między innowacją a stabilnością
Jak wdrożyć SRE w organizacji?
Kroki do efektywnego wdrożenia SRE
Wdrożyć SRE w organizacji to proces, który wymaga starannego planowania i stopniowej transformacji. Oto kluczowe kroki:
- Ocena obecnego stanu - Analyse der Betriebsabläufe ("procesów operacyjnych")
- Definiowanie celów - ustalenie konkretnych wskaźników sukcesu
- Wybór pilotażowego projektu - start z ograniczonym zakresem
- Budowanie zespołu - rekrutacja lub przekwalifikowanie inżynierów
- Implementacja narzędzi - wprowadzenie odpowiednich Plattform monitorowania
- Trening i edukacja - przeszkolenie wszystkich zespołów
Proces ten może trwać od kilku miesięcy do kilku lat, w zależności od wielkości i złożoności organizacji.
Die wichtigsten Fragen: Prometheus vs. Grafana
Wybór właściwych narzędzi jest kluczowy dla sukcesu implementacji SRE. Prometheus i Grafana to dwa fundamentalne narzędzia w ekosystemie SRE:
Prometheus służy do zbierania i przechowywania metryk, oferując:
- Potężny język zapytań (PromQL)
- Wbudowane mechanizmy alertowania
- Łatwą integrację z Kubernetes
- Wysoką wydajność przy dużych wolumenach danych
Grafana komplementuje Prometheus, dostarczając:
- Zaawansowane dashboardy i wizualizacje
- Integrację z wieloma źródłami danych
- Elastyczne możliwości konfiguracji alertów
- Współdzielenie raportów między zespołami
Szkolenie zespołu i zmiany w infrastrukturze
Transformacja w kierunku SRE wymaga inwestycji w rozwój zespołu i modernizację infrastruktur. Programiścimuszą nauczyć się myśleć o operacyjnych Aspekt swojego kodu, podczas gdy administratorzy muszą rozwinąć umiejętności programmistyczne.
Kluczowe obszary szkoleń obejmują:
- Narzędzia automatyzacji jak Ansible i Terraform
- Plattformy konteneryzacji (Kubernetes)
- Języki skryptowe i programowanie
- Metodologie zarządzania incydentami
- Projektowanie systemów odpornych na awarie
Wie sieht es bei SRE aus?
Definiowanie Service Level Objectives (SLO)
Service Level Ziele (SLO) zu fundamentalne wskaźniki w SRE, które definiują oczekiwany poziom niezawodności Dienstleistung. SLO są oparte na Indikatoren für Dienstgüte (SLI) - konkretnych metrykach, które można zmierzyć.
Przykładowe SLI i SLO:
- Dostępność: 99.9% czasu działania w miesiącu
- Standzeit: 95% mit einer Laufzeit von <200ms
- Przepustowość: obsługa minimum 1000 zapytań na sekundę
SLO Sie müssen realistisch sein, denn sie können nicht einfach in den Himmel kommen, ohne dass sie die Möglichkeit haben, sich zu verändern. Dienstleistung.
Jak monitorować dostępność i wydajność?
Überwachung dostępności i wydajności w SRE opiera się na trzech fundamentalnych pytaniach:
- Czy System działa? (dostępność)
- Czy użytkownicy są zadowoleni? (wydajność)
- Czy System jest zdrowy? (saturacja i błędy)
SRE "Goldene Signale":
- Latenzzeit - czas odpowiedzi
- Verkehr - obciążenie systemu
- Fehler - częstotliwość błędów
- Sättigung - wykorzystanie zasobów
Te wskaźniki dają kompleksowy obraz zdrowia systemu i pozwalają przewidzieć potencjalne problemy.
Rola metryk w zarządzaniu usługami
Metryki w SRE to nie tylko liczby - to podstawa podejmowania decyzji biznesowych. Każda metryka musi być:
- Handlungsfähig - prowadzić do konkretnych działań
- Erreichbar - łatwo dostępna dla wszystkich zespołów
- Erschwinglich - efektywna kosztowo w zbieraniu i przechowywaniu
SRE używają metryk do:
- Zwiększenia niezawodności poprzez identyfikację problemów
- Optymalizacji wydajności systemów
- Planowania pojemności i skalowania
- Demonstrowania wartości biznesowej inżynierii niezawodności
Wie sieht es mit der SRE aus?
Radzenie sobie z przestojami i incydentami
Przestoje są nieuniknione nawet w najlepiej zaprojektowanych systemach. SRE nie dąży do eliminacji wszystkich incydentów, ale do minimalizacji ich wpływu i uczenia się z każdego zdarzenia.
Kluczowe strategie to:
- Projektowanie systemów odpornych na awarie (widerstandsfähiges Design)
- Implementacja circuit breakers i mechanizmów fail-safe
- Automatyczne przełączanie na systemy zapasowe
- Regularne testy odporności (chaos engineering)
SRE traktuje każdy incydent jako możliwość nauki i ulepszenia systemów.
Wyzwania w zakresie automatyzacji
Automatyzacja w SRE niesie ze sobą własne wyzwania:
- Zawodne Skrypty mogą powodować większe problemy niż te, które miały rozwiązać
- Überautomatisierung kann zu einer Überlastung des Haushalts führen systemów
- Utrzymanie i aktualizacja zautomatyzowanych procesów wymaga zasobów
SRE musi znajdować równowagę między automatyzacją a zachowaniem kontroli nad systemami.
Współpraca z różnymi zespołami
SRE musi współpracować z wieloma zespołami o różnych priorytetach:
- Zespoły programistyczne chcą szybko wdrażać nowe funkcje
- Zespoły biznesowe oczekują ciągłości działania
- Zespoły bezpieczeństwa wymagają compliance i audytowalności
Sukces SRE zależy od umiejętności komunikacji i znajdowania kompromisów między różnymi wymaganiami.
Podsumowanie
SRE to więcej niż metodologia - to transformacja sposobu myślenia o systemach informatycznych. Standortzuverlässigkeitstechnik łączy najlepsze praktyki inżynierii oprogramowania z operacyjną ekspertyzą, tworząc podejściektóre pozwala organizacjom osiągnąć niespotykane poziomy niezawodności i wydajności.
Die neue Regierung SRE wymaga czasu, zasobów i kulturowej transformacji, ale korzyści - w postaci zwiększonej dostępności, redukcji kosztów operacyjnych i większej satysfakcji klientów - są znaczące. W produkcyjnymśrodowisku, gdzie każda minuta przestoju ma realne konsekwencje biznesowe, SRE staje się nie opcją, ale koniecznością.
Przyszłość należy do organizacji, które potrafią połączyć innowację z niezawodnością - i SRE jest kluczem do osiągnięcia tej równowagi.

 Dominik Szulim
Dominik Szulim






 Dominik Papaj
Dominik Papaj